
Javier Sánchez Soriano
PhD in Artificial Intelligence, Associate Professor, Higher Polytechnic School, Francisco de Vitoria University
Gonzalo de las Heras de Matías
Degree in Computer Engineering UFV, Master's Degree in Big Data UEM, Doctor of Applied Information Technologies UEM.
Enrique Puertas Sanz
European University of Madrid. Computer Engineering from the UEM, Doctor of Applied Information Technologies from the UEM.
Javier Fernández Andrés
European University Madrid. Industrial Technical Engineering ICAI, Industrial Engineering UPM. PhD Industrial Engineer UPM.
ADVANCED DRIVING AID SYSTEM (ADAS) AT ROUNDABOUTS USING AERIAL IMAGERY AND ARTIFICIAL INTELLIGENCE TECHNIQUES TO IMPROVE ROAD SAFETY
ADVANCED DRIVING AID SYSTEM (ADAS) AT ROUNDABOUTS USING AERIAL IMAGERY AND ARTIFICIAL INTELLIGENCE TECHNIQUES TO IMPROVE ROAD SAFETY
Summary: 1.- INTRODUCTION. 1.1.- Background. 1.2.- Capacity of roundabouts. 1.3.- Object detection. 1.4.- Object detection in aerial imagery. 2.- METHODOLOGY. INSTALLATION AND CALIBRATION PHASE. 2.1.- Installation and calibration phase. 2.2.- Implementation phase. 3.- RECOGNITION OF THE ROUNDABOUT. 3.1.- Preprocessing. 3.2.- Calculation of circumferences. 3.3.- Results. 4.- VEHICLE DETECTION. 4.1.- Dataset. 4.2.- Metrics. 4.3.- Experiments. 4.4.- Results 5.- INFORMATION EXTRACTION. 6.- CONCLUSIONS 7..- REFERENCES
Abstract: Roundabouts are a type of traffic construction in which several roads converge and communicate through a rotating circulation around a central island. Although, they have increased safety, driving around them properly is not an easy task for conventional and autonomous vehicles. There are publications about ADAS that considers roundabouts as objects to be transited, guiding these autonomous ones in the circulation. This work present takes roundabouts as a source of information that could be transmitted to these vehicles to improve their decision making. To this end, it details the creation of a prototype for monitoring Spanish roundabouts using aerial imagery and machine learning. This system requires an installation phase in which it is calibrated using image processing techniques to recognize the circumferences of the central island and the different lanes. Then, using a RetinaNET model based on a resnet50 backbone, each vehicle and its type is detected. Combining both subsystems, the prototype extract information about the position of vehicles (exact location and lane), entering/exiting ones and those that affect the entering (key aspect for capacity calculation). The aim is to improve security by using artificial intelligence techniques.
Resumen: Las rotondas son un tipo de construcción vial en el que confluyen varios caminos que se comunican a través de un anillo mediante una circulación rotatoria. Estas han traído un aumento en la seguridad, sin embargo, su correcta circulación no es tarea fácil, tanto para vehículos convencionales como autónomos. Existen publicaciones sobre ADAS (Sistema Avanzado de Ayuda a la Conducción) que toman a las rotondas como un objeto por el que transitar, guiando a estos últimos en la circulación. Este trabajo toma la propia rotonda como fuente de información la cual podría transmitirse a estos vehículos para mejorar su toma de decisiones. Para ello, se detalla la creación de un prototipo para la monitorización de rotondas españolas mediante imágenes aéreas y aprendizaje automático. Este sistema requiere de una fase de instalación por la cual se calibra mediante técnicas de tratamiento de imágenes para reconocer las circunferencias de la isleta principal y los distintos carriles. Seguidamente, usando un modelo de RetinaNET basado en resnet50, se localiza cada vehículo. Con esta información se extrae información útil tanto para monitorización de la rotonda, como para los vehículos que transitan por ella (autónomos y convencionales). Todo ello, con el fin de mejorar la seguridad haciendo uso de técnicas de inteligencia artificial.
Keywords: Roundabouts, Machine Learning, Aerial Imagery, Object Detection, Deep Learning, Computer Vision.
Palabras clave: Rotondas/Glorietas, Aprendizaje Automático, imágenes aéreas, Detección de Objetos, Aprendizaje profundo, Visión por Computador.
1.1.- Background
Road fatalities are a problem in today's society. They are the leading cause of death among children and young people aged 5-29 and cause 1.3 million deaths worldwide each year. (World Health Organization, 2021). Taken from an economic perspective, they account for 3% of each country's GDP (Gross Domestic Product). (World Health Organization, 2021). The World Health Organisation (WHO), in its report (World Health Organization, s.f.) identified several areas for improvement including but not limited to safer roads, greater awareness/training and safer vehicles. As part of the latter, the GIDS (Generic Intelligent Driver Support) project (Michon, 1993) laid the foundations for the so-called ADAS (Advanced Driver Assistance Systems) to improve the safety and comfort of drivers on the road (closely related aspects (Dirección General de Tráfico - Ministerio del Interior., 2018)). ADAS systems develop on classic safety systems such as ABS (Antilock Braking System), ESP (Electronic Stability Program), airbags or cruise control and have been key in the creation of autonomous vehicles (BCG, 2015). These ADAS can be subdivided depending on the type of sensors they employ (Kukkala et al., 2018): cameras, LiDAR, radar, ultrasound, etc.
Autonomous vehicles are those that, ideally, drive like a human without requiring human intervention. They simply employ different ADAS to interpret the surroundings and make decisions. There are 6 levels of autonomy ranging from total driver dependence (level 0) to total autonomy (level 5). (BCG, 2015). At present, there are several companies such as Telsa, Waymo or Baidu producing autonomous vehicles (Badue et al., 2019). However, there are still reports of accidents (BBC, 2021; The New York Times, 2021) (which even raise legal questions as to who is responsible (BBC, 2020)) and errors discovered that require inspection (Popular Science, 2021). The highest level of autonomy achieved is level 4. Autonomous driving is no mean feat, there are too many constraints and situations that the vehicle must interpret (speeds, road conditions, other vehicles) and handle (Naranjo et al., 2007). Some of these are already addressed by some ADAS, such as cruise control, lane change/keep assist or automatic parking (Kukkala et al., 2018).
One of the most difficult situations for autonomous vehicles to interpret are roundabouts (Rodrigues et al., 2017). According to the DGT, "roundabouts are a special type of intersection characterised by the fact that the sections that converge there connected by a ring in which a rotary traffic flow is established around a central traffic island" (Rodríguez, 2014). In a way, they can be viewed as several T-junctions in a row (Brilon W. , 1991). Spanish regulations indicate the following (Rodríguez, 2014; Dirección General de Tráfico, 2021):
1. Vehicles on the roundabout have priority over those wishing to join. It is not like at an intersection, where priority is given to vehicles on the right.
2. Traffic always moves in an anti-clockwise direction.
3. The driver can choose the lane that best suits their path. However, always exit the roundabout from the outside lane. If the outside lane is occupied, they must go around the roundabout again.
4.
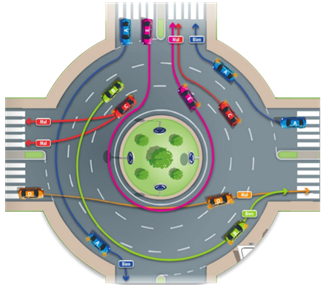 |
Direction indicators must be used to change lanes within the roundabout and to exit the roundabout. In the case of the latter, this shall not be before having passed the previous exit (illustrated on the green vehicle in Figure 1).
Figure 1. Representation of correct (blue and green vehicles) and wrong (orange, pink and red) paths (Rodríguez, 2014).
There are different types of roundabouts (García Cuenca et al., 2019) which can be classified depending on the aspect to be highlighted(Gallardo, 2005):
· Mode of operation: Depending on how they work, there are: roundabouts that operate via braided merging (Figure 2-A), roundabouts with priority to the right, i.e. inbound traffic has priority over traffic already on the roundabout, roundabouts with priority in the ring (Figure 2-B) and roundabouts with traffic lights in the ring (Figure 2-C).
· Geometry: Roundabouts can take different on geometric shapes. There are examples of circular, oval, double roundabouts (Figure 2-D) or even split roundabouts where two lanes cross the main island (Figure 2-E).
· Depending on the diameter: Large roundabouts (with an inner diameter of more than 20 metres), compact roundabouts (between 4 and 20 metres) and mini-roundabouts (smaller than 20 metres). The latter are usually found in areas where space is limited.
· Location: There are urban roundabouts, where the speed on the roads leading to them are no more than 50km/h, as opposed to semi-urban roads, where the speed on these roads can be higher. There are also out-of-town roundabouts on interurban roads and roundabouts that are crossed by roads at different levels (Figure 2-F).
|
|
|
|
|
(A) |
(B) |
(C) |
|
|
|
|
|
(D) |
(E) |
(F) |
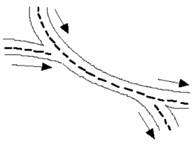
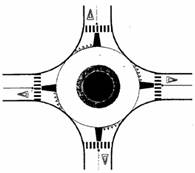
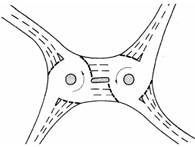
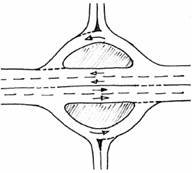
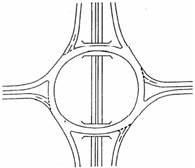
Figure 2. Examples of different types of roundabout: (A) braiding, (B) priority in the ring, (C) with traffic lights, (D) double roundabout, (E) split roundabout, (F) roundabout with different levels (Gallardo, 2005).
With regard to autonomous vehicles, several publications have researched the problem posed by roundabouts. They mainly consider scenarios in which autonomous cars must learn to manoeuvre (García Cuenca et al., 2019; García Cuenca et al., 2019). The aim of this publication is to create a prototype for a system capable of extracting information from the roundabout (limited to circular roundabouts with ring priority as they are the most common type (Gallardo, 2005)) using aerial images and machine learning techniques, not only to provide information to autonomous vehicles, but also to drivers of conventional vehicles The information considered relevant is the location of the vehicles at the roundabout (position and lane) from which useful information can be extracted regarding the status of the roundabout, which other systems deliver to the vehicles to facilitate its movement.
One of the key issues in assessing performance at roundabouts is to calculate the capacity of the roundabout (Bernhard & Portmann, 2000). This can be considered as a function of the geometry, the entry/exit capacity of the roundabout and the characteristics of drivers and vehicles (Gallardo, 2005). Entry capacity is defined as the maximum flow entering the roundabout from an entrance, by vehicles waiting to merge (Gibson & Waterson, 2013). This depends on several factors such as roundabout geometry (Mauro & Guerrieri, 2012; Tollazzi et al., 2011; Silva et al., 2014; Yap et al., 2015), different environmental factors (Yap et al., 2013; Montgomery et al., 2010), drivers' demand in relation to entrances and exits (Yap et al., 2013; Akçelik, 2004; Hagring, 2000), pedestrians in the vicinity and on the roundabout as well as possible obstructions inside the roundabout (Yap et al., 2013; Marlow & Maycock, 1982). Due to the complications posed by data collection, multiple estimation methods have been developed and are classified into: empirical methods based on geometry and capacity measurements, gap acceptance models that take into account driver behaviour and microscopic simulation models that model vehicle kinematics and interactions (Bernhard & Portmann, 2000; Yap et al., 2013; Macioszek, 2020). However, despite the similarity of roundabout designs around the world, there can be large differences in the application of different models for calculating capacity (Yap et al., 2015).
Empirical
models are based on parameter settings relating roundabout geometry and
capacity measurements. These models are created by multivariate regressions
using input capacity (![]() ), traffic flow (
), traffic flow (![]() ) and other variables affecting
capacity. The relationship between
) and other variables affecting
capacity. The relationship between ![]() and
and ![]() is presumed to be linear (1) or
exponential (2) (Yap et al., 2013).
is presumed to be linear (1) or
exponential (2) (Yap et al., 2013).
|
|
(1). |
|
|
(2). |
Examples are LR942 (Kimber, 1980) or French Girabase (Guichet, 1997). Machine learning is also useful in this field. Publications such as (Anagnostopoulos et al., 2021) report on calculating capacity using neural networks, which can also be used to discover which variables actually affect capacity.
Gap
Acceptance is based on theoretical models using parameters obtained from
measurements between vehicles travelling on the roundabout and those about to
join (Yap et al., 2013). The input capacity is calculated using 3 parameters:
the critical gap gap (![]() ), follow on headway (
), follow on headway (![]() ) and the distribution of gaps in
traffic on the roundabout. Examples can be seen in German Brilon-Wu (Brilon et
al., 1997) or SR45/SIDRA. (Troutbeck, 1989).
) and the distribution of gaps in
traffic on the roundabout. Examples can be seen in German Brilon-Wu (Brilon et
al., 1997) or SR45/SIDRA. (Troutbeck, 1989).
Microscopic simulations model vehicle movements and interactions. The major advantage of these is their ability to simulate different scenarios for adequate study (Yap et al., 2013). Both commercial models, including but not limited to S-Paramics (Microsimulation, 2011), Aimsun (Systems, 2011) and SUMO (Behrisch et al., 2011) can be found as well as other more theoretical models dedicated to the study of different situations (Chin, 1985; Chung et al., 1992).
1.3.- Object Detection
Perception of the surrounding area is very important for ADAS. There are different sensors capable of providing information, although when it comes to object recognition, cameras or LiDAR are the most important, and the current debate is about which is the best solution (O'Kane, 2018). Prior to the advent of neural networks and deep learning, these object recognisers operated with limited computational resources and relied on handmade features (Zou et al., 2019). Examples of these can be seen in the Viola Jones face recogniser (Viola & Jones, 2004; Viola & Jones, 2001), the HOG pedestrian recogniser (Histogram of Oriented Gradients) (Zou et al., 2019; Dalal & Triggs, 2005)), or the DPM (Deformable Part-based Model) (Zou et al., 2019; Felzenszwalb et al., 2008).
Machine learning is a branch of artificial intelligence that is distinguished by the system's ability to train itself. This is further subdivided into two broad groups: supervised and unsupervised learning. The difference between them lies in the way the system learns. While supervised learning requires a series of pre-labelled examples, unsupervised learning does not rely on them.
Within the supervised learning group, neural networks are worth particular mention, including convolutional neural networks, which became very popular in 2012 (Krizhevsky et al., 2017). Their main quality is that they are a very specific type of network that can extract features present in an image, making them a very suitable algorithm for image classification (Krizhevsky et al., 2017; Girshick, 2015) and object detection (Girshick, 2015; Girshick et al., 2013; Sermanet et al., 2013). The latter are further subdivided into single-stage and two-stage networks. Examples of two-stage networks are R-CNN (Girshick et al., 2013), Fast R-CNN (Girshick, 2015) or Faster R-CNN (Zou et al., 2019; Ren et al., 2017). One-stage networks include the YOLO (You Only Look Once) networks in their different versions v1 (Redmon et al., 2016), v2/9000 (Redmon & Farhadi, 2017), v3 (Redmon & Farhadi, 2018), v4 (Bochkovskiy et al., 2020) as well as other alternatives such as SSD (Single Shot Detector) (Liu et al., 2016) or RetinaNet (Lin et al., 2020). Each type has a number of advantages, e.g., one-stage is faster, but lacks as much precision. (Soviany & Ionescu, 2018).
RetinaNet has been chosen for this paper as it offers a good balance between accuracy and speed and is competent when compared to other models (Tan et al., 2021), and has been used successfully in (De-Las-Heras et al., 2021; Stuparu et al., 2020).
1.4.- Object Detection in Aerial Imagery
Object detection in aerial imagery has proven useful in multiple applications such as 3D mapping (Elkhrachy, 2021), agriculture (Dijkstra et al., 2019) or disaster assessment (Gupta et al., 2021). This technology has also proven to be effective in tasks related to vehicles and their infrastructure. There are numerous papers about vehicle recognition in aerial images (Stuparu et al., 2020; Shen et al., 2021; Liu & Mattyus, 2015; Zhong et al., 2017; Tang et al., 2020; Deng et al., 2017; Yu et al., 2019; Chen et al., 2015; Kembhavi et al., 2010) or infrastructure (Cheng et al., 2017) and even pedestrian recognition in this type of images, a process which is more complex given their relative size compared to vehicles (Chang et al., 2018; Soleimani & Nasrabadi, 2018).
As we have seen in the previous section, Deep learning models used in object recognition require a series of previously labelled examples for training. A variety of aerial image datasets are currently available (Krajewski et al., 2018; Bock et al., 2020; Robicquet et al., 2016; Du et al., 2018; Bock et al., n.d.; Krajewski et al., n.d.), including some more specific and related to roundabouts (Puertas et al., 2022) as well as vehicle paths on roundabouts (Krajewski et al., 2020; Breuer et al., 2020). These are very useful, but are usually not easily and quickly accessible due to their commercial use.
For the capture of aerial images, in addition to the use of satellites or aircraft with high operating costs, the use of UAS (Unmanned Aircraft Systems) or drones has proliferated. This technology is very promising when it comes to accessing hard-to-reach places and sending high-resolution images in real time at an affordable cost. These complement the object detection process discussed in the previous paragraphs very well, as these drones send images to the processing system, which extracts information. This would be typical architecture, as image processing requires high processing power, provided by GPUs (Graphics Processing Unit).
2.- METHODOLOGY
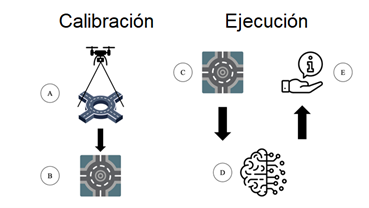 |
The methodology pursued in the development of this research paper is reflected in Figure 3. It consists of a two-stage process: (1) Installation and Calibration and (2) Execution. These phases and their steps are described in the following subsections.
Figure 3. Operation of the prototype with its two phases: Calibration and Implementation.
2.1.- Installation and Calibration Phase
An installation phase is required before capturing and processing the aerial imagery. To this end, the camera device is placed in the centre of the roundabout at a given height (Figure 3-A), meaning the roundabout is deformed as little as possible. In this case and to validate this work, a UAS or drone was used. Specifically, a Mavic Mini 2 civil aircraft manufactured by DJI was used (DJI, s.f.), equipped with a camera for which the characteristics are reflected in Table 1. The flight range of the device is 30 minutes with the battery at full charge and in favourable weather conditions (no wind and medium to low ambient temperature).
However, once the system is in production, the simplest option would be to use a pole in the centre of the roundabout with a 360° camera system, so that a birds-eye view of the roundabout is generated by compositing the images. Many roundabouts already feature these poles for lighting, so they could be reused for the combined installation of the camera system.
|
Component |
Specification |
|
Resolution |
1920x1080 px |
|
FOV angle |
83º |
|
Focal (35 mm) |
24 mm |
|
Opening |
f/2.8 |
|
Aspect ratio |
19:9 |
|
Sensor |
1/2.3" CMOS |
Table 1. UAS camera specifications
The next step, regardless of the capture system used (UAS or pole-mounted 360° camera), would be the calibration of the aerial images by a semi-automated process in order to recognise and define the lanes (Figure 3-BC). This process is described in section 3 below.
2.2.- Implementation Phase
Once the system has been prepared following the installation and calibration phase, using a convolutional neural network previously trained and tuned (Figure 3-D), each vehicle is recognised and information is extracted from the roundabout regarding its position thereon (Figure 3-E). The hardware used in the prototype to process the aerial images is shown in Table 2.
|
Component |
Specification |
|
Processor |
Intel i7 9800K 3.6 GHz |
|
Motherboard |
MPG Z390 Gaming Pro Carbon |
|
Memory |
32 GBs |
|
Graphics |
Nvidia RTX 2080 Ti |
|
Storage |
500 Tb SSD M2 |
|
Operating System |
Ubuntu 18.04.4 LTS |
Table 2. Specifications of the prototype used for testing
3.- RECOGNITION OF THE ROUNDABOUT
From the processing pipeline, the first step is to calculate the centre and radius of the circumferences that make up the central island and each of the lanes, so that the recognition of vehicles and their position within the different sections of the roundabout can be correctly detected. This is important given the existence of different types of roundabouts (García Cuenca et al., 2019) and the different heights at which the camera could be placed, meaning the system requires prior calibration.
3.1.- Preprocessing
Before recognising the circumferences that make up the roundabout (the centre island and the individual lanes), it is necessary to perform preliminary processing. This consists of applying a series of transformations to the image to facilitate recognition and adjust it to what the algorithms require. The steps are as follows:
Region of interest. Since the position of the camera can be chosen, it is assumed that the central island will be within certain coordinates. This makes it possible to erase certain parts of the image that are unnecessary and that will therefore only add noise to the recognition. This is a technique used in deep learning (Kim et al., 2018). The region of interest (RoI) set on the original image (Figure 4) is a box at coordinates (300, 100) and (1620, 980) as shown in Figure 5.
 |
 |
Figure 4. Raw image captured from the drone.
Figure 5. RoI applied to the image.
Noise removal and smoothing. Within the image, there are many silhouettes that provide a number of traces within the image. Using the dilation morphology operation (OpenCV, n.d.; Gonzalez et al., 2009; Sreedhar & Panlal, 2012) and a Gaussian filter (OpenCV, n.d.; Gonzalez et al., 2009) (both with a kernel of (9, 9)), those with small discontinuities are closed and the image is smoothed. Next, the remainder is calculated between an absolute blank image difference (OpenCV, s.f.) between the original image with the RoI and the one obtained after the previous Gaussian filter, to obtain an image with a white background and grey lines (Figure 6). Finally, a threshold function is applied whose experimentally calculated parameters are thresh=230, maxval=0 and standard THRESH_TRUNC (1). (OpenCV, s.f.).
|
|
(3). |
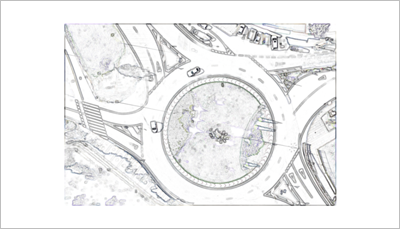
Figure 6. Pre-processed image.

Edge calculation. The last step involves obtaining
an image that uses only the edges of the objects in the image (Figure 7), as
this is the real requirement for the detection of the circumferences. This is
achieved using the Canny algorithm (Canny, 1986; Gonzalez et al., 2009; Rebaza,
2007; OpenCV, n.d.) to which a Gaussian filter of (7, 7) has been previously
applied. The choice of the Canny parameters automatic by means of (Rosebrock, 2015)used and tested in other papers such as (De-Las-Heras et al., 2021).
Finally, the dilation morphology operation with a kernel (2, 2) is applied to
highlight the strokes.
Figure 7. Image after applying the Canny algorithm.
3.2.- Calculation of Circumferences
Thanks to the image obtained in the previous step, it is now ready to be processed by the algorithm that calculates the centre and radius of the central island of the roundabout, as well as the lanes. The Hough transform (Gonzalez et al., 2009; OpenCV, n.d.; Shehata et al., 1962; Ballard & Brown, 1982) is an algorithm that recognises straight lines in images. It is very useful as it provides their equations as output. There is a version for calculating circumferences and ellipses (OpenCV, n.d.; ImageJ, n.d.; scikit-image, n.d.; Xie & Ji, 2002). As a result, the equation representing the main traffic island is obtained and together with data previously obtained, such as the number of lanes, lane width, the rest of the circumferences can be obtained (Figure 8).

Figure 8. Operation of the prototype.
3.3.- Results
Qualitatively, the pipeline recognises the central island quite accurately. However, a number of factors affecting recognition have been identified experimentally:
· Size of the roundabout. Larger roundabouts result in a longer processing time as there is a larger number of pixels to deal with.
· Vegetation in the image. Although the processing pipeline manages to remove much of the noise from the image, certain silhouettes belonging to vegetation remain. These cause errors when recognising the central circumference, meaning that it is sometimes identified inside the vegetation.
· Pavements at roundabouts. Some roundabouts have a small pavement that is shown as a small concentric circumference that may confuse the recogniser.
· Tarmac colours in the roundabout. This means the circumference is not sufficiently distinguishable from the tarmac, meaning that the traffic island is not recognised correctly.
· Irregular lane sizes. Some roundabouts do not have a fixed lane size. On some, the outermost lane is wider, such as the roundabout in Figure 10-D, which has entrance/exit corners that are slightly larger than the lane. This causes a small error in determining the separation of the different lanes.
All these factors are mitigated and the quality of roundabout recognition is improved by manually calibrating the RoI so that only the main traffic island is surrounded by asphalt. For the prototype, this is not a major setback as it is a calibration phase that is performed the first time the system is deployed. The results for each roundabout are shown in Figure 9.
|
(A) |
(B) |
|
(C) |
(D) |
|
(E) |
(F) |
|
(G) |
(H) |








Figure 9. Results obtained with a RoI customised to each roundabout.
4.- VEHICLE DETECTION
Once the circumferences and the RoI of the roundabout have been calculated, the next step is to recognise each of the vehicles on it. Since the aim of this publication is not to find the best recognition model per se, having reviewed the state of the art, a RetinaNet model (Lin et al., 2020) built using resnet50 has been selected since, as indicated above, machine learning has proven to be a very effective method in object localisation. Furthermore, this CNN has demonstrated strong performance in object recognition tasks (Tan et al., 2021; De-Las-Heras et al., 2021) and vehicle recognition in aerial images (Stuparu et al., 2020). Since this prototype is a system that must work in real time, i.e. its information is valid for a short period of time, the balance between model quality and recognition speed has been established as values to be optimised.
As an initial requirement for supervised learning algorithms, a dataset with previously annotated examples is required. In this case, (Puertas et al., 2022) has been used which is equipped with 947,400 cars, 19,596 bicycles, 2,262 trucks and 7,008 buses.
Data-augmentation consists of applying a series of transformations to training images in order to synthetically create new examples with which machine learning models can better generalise (Zoph et al., 2020). This has been tested in several projects with impressive results (De-Las-Heras et al., 2021; Stuparu et al., 2020). These techniques have already been applied to this dataset, in particular several samples. However, the following transformations and colour adjustments have been applied to increase dataset's potential and allow the model to generalise better:
· Rotations on the original image.
· Translations, moving the content of the image.
· Shear (Figure 10), crop the edges of the image resulting in the actual content as a parallelogram (Kathuria, s.f.).
· Increase or decrease the size of the image (scaling).
· Increases or decreases in image properties such as: brightness, contrast, hue and saturation.

Figure 10. Example of shearing (Kathuria, s.f.).
These transformations are applied randomly to each image individually during the training stage under the parameters indicated in Table 3 using the library (fizyr, s.f.).
|
Transformation |
Minimum value |
Maximum value |
|
|
Rotation |
-0.5 |
0.5 |
Radians |
|
Translation |
-0.5 |
0.5 |
Translation vector |
|
Shearing |
-0.5 |
0.5 |
Radians |
|
Scaling |
0.9 |
1.1 |
Scaling vector |
|
Brightness |
-0.1 |
0.1 |
Amount added to each pixel. |
|
Contrast |
0.9 |
1.1 |
Counting factor. |
|
Hue |
-0.05 |
0.05 |
Quantity added to the hue channel |
|
Saturation |
0.95 |
1.05 |
Multiplication factor |
Table 3. Parameters of data-augmentation.
Finally, the dataset has been divided into several portions (Table 4). 10% of the dataset has been set aside for the assessment of the model after it is trained. From the remaining 90%, another 90% has been devoted to the training itself, while the other 10% has been used to evaluate the model after each period.
|
81% Training |
9% Validation |
10% Evaluation |
Table 4. Division of the dataset.
The selection of which set each image belongs to has been performed randomly taking into account that the dataset is unbalanced between classes. Thus, approximately 81% of the examples of each class are in the training set, 9% in the validation set and 10% in the evaluation set. This ensures sufficient representation of each class in each set.
4.2.- Metrics
As discussed above, the metrics of interest for the prototype are inference time and model quality. In relation to the latter, the mAP (Mean Average Precision) has been selected, as used in other publications to demonstrate the suitability of the model (De-Las-Heras et al., 2021; Stuparu et al., 2020; Everingham et al., 2010). This is defined as the mean of the APs of each class (4), where the AP is the area under the coverage-precision curve (5), calculated by (5) and (6). To calculate both coverage and accuracy, an IoU (Intersection over Union) of 0.5 has been defined. This means that an overlap of at least 50% between the actual and predicted bounding box is required to consider a detection as positive.
|
(4). |
|
|
|
(5). |
|
|
(6). |
|
|
(7). |
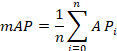
4.3.- Experiments
For the experiments in relation to neural network training, the following scenarios have been performed taking into account the results of (Stuparu et al., 2020):
1. Normal mode.
The first experiment was simply to train the Retinanet model with the dataset and conditions detailed in the previous section. The best model has been selected using the highest mAP found for the evaluation set. The results are shown in Table 5.
|
|
Minimum Score = 0.05 |
Minimum Score = 0.5 |
||
|
Classes |
AP@50 |
AP@75 |
AP@50 |
AP@75 |
|
Car |
0.9976 |
0.9409 |
0.9967 |
0.9401 |
|
Bicycle |
0.8496 |
0.4695 |
0.8345 |
0.4683 |
|
Lorry |
0.9624 |
0.7886 |
0.9562 |
0.7858 |
|
Bus |
0.9654 |
0.5337 |
0.9234 |
0.5125 |
|
mAP |
0.6832 |
0.6767 |
||
Table 5. 2000x2000px model results (0.07 s. of inference per image).
2. Scaling in image size.
This experiment has been proposed based on the observations of (Stuparu et al., 2020) where increasing the size of the images led to better results. To this end, the original image size (1920x1080px) was originally multiplied by 2, resulting in 3840x2160px images. However, this size resulted in constant training errors because the available hardware had insufficient computing power to handle such large images. Thus, the scaling factor was changed from 2 to 1.5, generating (2880x1620px) images that do work with the available hardware. With this configuration, an inference time per image of 0.1817 seconds was achieved. This training was not pursued as this time was considered too long.
After this experiment, another one was carried out, reducing each dimension of the image by half. It was also ruled out because the Cycle class frames were so small that the model did not recognise any (its AP was 0).
3. Extract the roundabouts by generating a new dataset.
For the last experiment, the roundabout recognition work (explained in the section) was taken to generate a new dataset consisting only of square images containing the roundabout itself. This has the advantage of removing part of the image that is of no interest. However, this involves rescaling all images to the same size, which means that smaller images have to be scaled much more. This adversely affects their quality. This experiment has been carried out using 1000x1000px and 2000x2000px images, the results of which can be found in Tables 6 and 7:
|
|
Minimum Score = 0.05 |
Minimum Score = 0.5 |
||
|
Classes |
AP@50 |
AP@75 |
AP@50 |
AP@75 |
|
Car |
0.9892 |
0.9720 |
0.9776 |
0.9658 |
|
Bicycle |
0.6234 |
0.1651 |
0.5057 |
0.1430 |
|
Lorry |
0.9881 |
0.9699 |
0.9714 |
0.9556 |
|
Bus |
0.9739 |
0.9261 |
0.9242 |
0.8978 |
|
mAP |
0.8937 |
0.7583 |
0.8447 |
0.7406 |
Table 6. 1000x1000px model results (0.04 s. of inference per image).
|
|
Minimum Score = 0.05 |
Minimum Score = 0.5 |
||
|
Classes |
AP@50 |
AP@75 |
AP@50 |
AP@75 |
|
Car |
0.6899 |
0.6529 |
0.6576 |
0.6404 |
|
Bicycle |
0.0414 |
0.0067 |
0.0000 |
|
|
Lorry |
0.4317 |
0.4071 |
0.2978 |
0.2893 |
|
Bus |
0.4639 |
0.3885 |
0.2443 |
0.2261 |
|
mAP |
0.4067 |
0.3638 |
0.6899 |
0.2889 |
Table 7. 2000x2000px model results (0.17 s. of inference per image).
4.4.- Results
Based on these results, the models obtained from the first experiment, measured with AP@50 with the minimum score of 0.05 and 0.5 (0.9438 and 0.9277), are the most promising. To make the best decision, the F1-score (8) for both has been calculated. The results are as follows: 0.483 and 0.983. Based on this result, the second model was chosen as the latter metric is far superior to that of the former, even though the former has a better mAP than the latter. In general, the model works well (Figures 11 and 12). However, a number of detection errors have been observed with urban elements (portions of traffic islands, bus shelters, containers, etc.), black vehicles, cars on a zebra crossing or in dark areas and vehicles.
|
|
(8). |

Figure 11. Results of the vehicle detection model (part 1).

Figure 12. Results of the vehicle detection model (part 2).
5.- INFORMATION EXTRACTION
Once the vehicle detector has been obtained, the next step is to extract the information about the roundabout. By studying the capacity calculation of these roundabouts (section 1.2), it has been identified that a lot of information of interest is located in specific parts of the roundabout. As a result, the system provides the following information:
1. Position and type of vehicle on the roundabout. This information is immediate as it is the output of the Deep Learning model achieved in the previous step.
2. Traffic per lane. Using the information from the circles obtained in section 3 and the output from the vehicle detector, the Euclidean distance between them is calculated to find out which lane it is in. A very common measure to express the amount of traffic is the PCU (Passenger Car Unit) (Mauro, 2010), which weights the type of vehicle by assigning a certain amount based on the physical space it occupies (Table 8).
|
Type of vehicle |
PCU |
|
Car |
1 pcu |
|
Lorry/Bus |
1.5 pcu |
|
Lorry with trailer |
2 pcu |
|
Motorcycle/Bicycle |
0.5 pcu |
Table 8. PCU units by vehicle type.
3.
Traffic disturbing
a new joiner (incoming, outgoing and circulating traffic). One of the keys to
calculating entry capacity at a roundabout is the traffic that affects entry in
some way (Figure 13). Publications define this as disturbance flow (![]() ) which, depending on the
calculation method used, either simply include the moving traffic in front of
the roundabout (
) which, depending on the
calculation method used, either simply include the moving traffic in front of
the roundabout (![]() ) or include outgoing (
) or include outgoing (![]() ) and incoming (
) and incoming (![]() ) traffic (Mauro, 2010). Figure 15
illustrates each of these measurements. To identify all these situations, this
area of influence must be defined (Figures 14 and 15) and check whether a
vehicle is in them.
) traffic (Mauro, 2010). Figure 15
illustrates each of these measurements. To identify all these situations, this
area of influence must be defined (Figures 14 and 15) and check whether a
vehicle is in them.
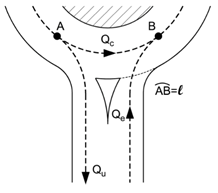 |
Figure 13. Diagram of disruptive traffic when joining a roundabout.
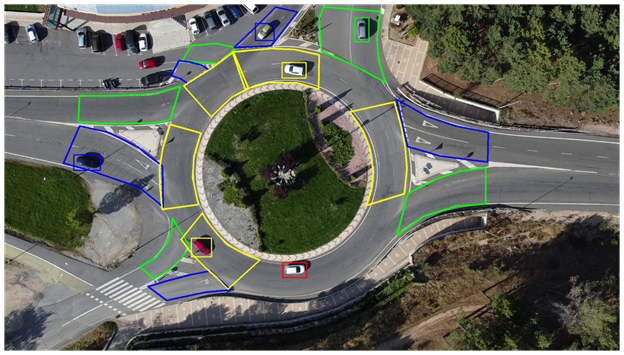
Figure 14. Determination of the different areas of a roundabout. (blue: entrance, green: exit, yellow: circulating traffic, red: rest).

Figure 15. Vehicles belonging to each area (blue: entrance, green: exit, yellow: circulating traffic, red: rest).
The main reason behind this paper was to provide a different point of view to the current literature on autonomous vehicles and roundabouts. Other publications treat them as a complicated scenario that these vehicles must learn to navigate. However, this paper considers them as a source of information consisting of aerial images of the roundabouts themselves that can be taken using UAS (drones) or a system of fixed cameras installed at a height with a mast in the centre of the roundabout.
In this paper, details have been provided about the process for developing an ADAS prototype for extracting information about Spanish roundabouts from aerial images of these roundabouts. It is divided into two parts. The first is about recognising the circumferences of the central island and the lanes. This has been achieved with computer vision techniques previously used in other areas, but not specifically on roundabouts. Second, using a Deep Learning model, with a mAP of 0.9277 (higher than other similar publications), vehicles are detected. Next, information is extracted on the condition of the roundabout: vehicles at entrances/exits, those disrupting merging traffic and the location of each vehicle in the different lanes.
The use of aerial images taken from UAS (drones) has allowed the ADAS prototype to monitor the condition of roundabouts without the need to install 360º cameras on poles in the centre of the roundabouts themselves (as explained in section 2), which has speeded up this study. Despite the limited range of these aircraft, their use would still be an interesting option in specific situations, for example in areas with a high concentration of roundabouts. These could be controlled with one or several UAS in certain episodes and on demand (peak hours, accidents, etc.). These UAS could also be used for different types of control missions in addition to providing this ADAS service.
In addition to the purpose of providing information to vehicles, this system is also useful in the study of roundabouts. The information extracted can be stored for further research, with a number of specific applications including the calculation of overall entrance capacity, peak hours and combined, with a unique vehicle identification system, as well as driver paths and conduct.
This improves traffic safety at roundabouts through the use of artificial intelligence.
7.- REFERENCES
· Akçelik, R. (2004). Roundabouts with unbalanced flow patterns. Paper presented at the Institute of Trans- portation Engineers 2004 Annual Meeting.
· Anagnostopoulos, A., Kehagia, F., Damaskou, E., Mouratidis, A., & Aretoulis, G. (2021). Predicting Roundabout Lane Capacity using Artificial Neural Networks. Journal of Engineering Science and Technology Review, 14, 210-215.
· Badue, C., Guidolini, R., Carneiro, R., Azevedo, P., Cardoso, V., Forechi, A., . . . De Souza, A. (2019). Self-Driving Cars: A Survey,.
· Ballard, D., & Brown, C. (1982). Computer vision. englewood cliffs. J: Prentice Hall.
· BBC. (2020, 09 16). Uber's self-driving operator charged over fatal crash. Retrieved 12 31, 2022, from https://www.bbc.com/news/technology-54175359
· BBC. (2021, 12 15). Tesla Model 3: Paris' largest taxi firm suspends cars after fatal crash. Retrieved 12 31, 2022, from https://www.bbc.com/news/world-europe-59647069
· BCG. (2015). A Roadmap to Safer Driving through Advanced Driver Assistance Systems. Retrieved 12 30, 2022, from https://image-src.bcg.com/Images/MEMA-BCG-A-Roadmap-to-Safer-Driving-Sep-2015_tcm9-63787.pdf
· Behrisch, M., Bieker, L., Erdmann, J., & Krajzewicz, D. (2011). SUMO - Simulation of Urban MObility.
· Bernhard, W., & Portmann, P. (2000). Traffic simulation of roundabouts in Switzerland. 2000 Winter Simulation Conference Proceedings (Cat. No.00CH37165), 2, 1148-1153.
· Bochkovskiy, A., Wang, C.-Y., & Liao, H.-Y. (2020). Bochkovskiy, Alexey, Chien-Yao Wang, and Hong-Yuan Mark Liao. "Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934.
· Bock, J., Krajewski, R., Moers, T., & Vater, L. (n.d.). UniD. The University Drone Dataset. Naturalistic Trajectories of Vehicles and Vulnerable Road Users Recorded at the RWTH Aachen University Campus. Retrieved 03 26, 2022, from https://www.unid-dataset.com/
· Bock, J., Krajewski, R., Moers, T., Runde, S., Vater, L., & Eckstein, L. (2020). The inD Dataset: A Drone Dataset of Naturalistic Road User Trajectories at German Intersections. 2020 IEEE Intelligent Vehicles Symposium (IV), 1929-1934.
· Breuer, A., Termöhlen, J.-A., Homoceanu, S., & Fingscheidt, T. (2020). OpenDD: A Large-Scale Roundabout Drone Dataset. Proceedings of International Conference on Intelligent Transportation Systems}.
· Brilon, W. (1991). Intersections Without Traffic Signals II: Proceedings of an International Workshop. Springer-Verlag.
· Brilon, W., Wu, N., & Bondzio, L. (1997). Unsignalized intersections in Germany — a state of the art 1997. Third international symposium on intersections without traffic signals, 61–70.
· Canny, J. (1986). A Computational Approach to Edge Detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, PAMI-8(6), 679-698.
· Chang, Y.-C., Huang, C., Chuang, J.-H., & Liao, I.-C. (2018). Pedestrian Detection in Aerial Images Using Vanishing Point Transformation and Deep Learning. 2018 25th IEEE International Conference on Image Processing (ICIP), 1917-1921.
· Chen, Z., Wang, C., Wen, C., Teng, X., Chen, Y., Guan, H., . . . Li, J. (2015). Vehicle detection in high-resolution aerial images via sparse representation and superpixels. IEEE Transactions on Geoscience and Remote Sensing, 54(1), 103-116.
· Cheng, G., Wang, Y., Xu, S., Wang, H., Xiang, S., & Pan, C. (2017). Automatic Road Detection and Centerline Extraction via Cascaded End-to-End Convolutional Neural Network. IEEE Transactions on Geoscience and Remote Sensing, 55(5), 3322-3337.
· Chin, H. C. (1985). SIMRO: A model to simulate traffic at roundabouts. Traffic Engineering and Control, 26, 109–113.
· Chung, E., Young, W., & Akçelik, R. (1992). Comparison of roundabout capacity and delay estimates from analytical and simulation models. 16th ARRB Conference, 16, 369–385.
· Dalal, N., & Triggs, B. (2005). Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 1, 886-893.
· De-Las-Heras, G., Sánchez-Soriano, J., & Puertas, E. (2021). Advanced Driver Assistance Systems (ADAS) Based on Machine Learning Techniques for the Detection and Transcription of Variable Message Signs on Roads. Sensors, 21(17).
· Deng, Z., Sun, H., Zhou, S., Zhao, J., & Zou, H. (2017). Toward fast and accurate vehicle detection in aerial images using coupled region-based convolutional neural networks. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 10(8), 3652--3664.
· Dijkstra, K., van de Loosdrecht, J., Schomaker, L. R., & Wiering, M. A. (2019). Hyperspectral demosaicking and crosstalk correction using deep learning. Machine Vision and Applications, 30, 1-21.
· Dirección General de Tráfico - Ministerio del Interior. (2021, 12 23). Código de Tráfico y Seguridad Vial. Retrieved 01 01, 2022, from https://www.boe.es/biblioteca_juridica/codigos/abrir_pdf.php?fich=020_Codigo_de_Trafico_y_Seguridad_Vial.pdf
· Dirección General de Tráfico - Ministerio del Interior. (2018). Cuestiones De Seguridad Vial. Retrieved 12 30, 2021, from http://www.dgt.es/Galerias/seguridad-vial/formacion-vial/cursos-para-profesores-y-directores-de-autoescuelas/XXI-Cuso-Profesores/Manual-II-Cuestiones-de-Seguridad-Vial-2018.pdf
· DJI. (n.d.). DJI Mini 2. Retrieved 03 26, 2022, from https://www.dji.com/ca/mini-2/specs
· Du, D., Qi, Y., Yu, H., Yang, Y., Duan, K., Li, G., . . . Tian, Q. (2018). The Unmanned Aerial Vehicle Benchmark: Object Detection and Tracking. European Conference on Computer Vision (ECCV).
· Elkhrachy, I. (2021). Accuracy Assessment of Low-Cost Unmanned Aerial Vehicle (UAV) Photogrammetry. Alexandria Engineering Journal, 60(6), 5579-5590.
· Everingham, M., Van Gool, L., & Williams, C. (2010). The Pascal Visual Object Classes (VOC) Challenge. International Journal of Computer Vision, 88, 303-338.
· Felzenszwalb, P., McAllester, D., & Ramanan, D. (2008). A discriminatively trained, multiscale, deformable part mode, computer vision and pattern recognition. 2008 IEEE Conference on Computer Vision and Pattern Recognition, 1-8.
· fizyr. (n.d.). Keras RetinaNet. Retrieved 04 05, 2022, from https://github.com/fizyr/keras-retinanet
· Gallardo, V. (2005). Funciones de las rotondas urbanas y requerimientos urbanísticos de organización.
· García Cuenca, L., Puertas, E., Fernandez Andrés, J., & Aliane, N. (2019). Autonomous Driving in Roundabout Maneuvers Using Reinforcement Learning with Q-Learning. Electronics, 8(12).
· García Cuenca, L., Sanchez-Soriano, J., Puertas, E., Fernandez Andrés, J., & Aliane, N. (2019). Machine Learning Techniques for Undertaking Roundabouts in Autonomous Driving. Sensors, 19(10).
· Girshick, R. (2015). Fast R-CNN. 2015 IEEE International Conference on Computer Vision (ICCV), 1440-1448.
· Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2013). Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.
· Gonzalez, R., Woods, R., & Masters, B. (2009). Digital image processing.
· Guichet, B. (1997). Roundabouts in France: Development, safety, design, and capacity. Proceedings of the third international symposium on intersections without traffic signals, 100–105.
· Gupta, A., Watson, S., & Yin, H. (2021). Deep learning-based aerial image segmentation with open data for disaster impact assessment. Neurocomputing, 439, 22-33.
· Hagring, O. (2000). Effects of OD Flows on Roundabout Entry Capacity. Fourth international symposium on highway capacity(434–445).
· Hough, P. (1962, 12 18). U.S. Patent No. US3069654A.
· ImageJ. (n.d.). Hough Circle Transform. Retrieved 01 16, 2022, from https://imagej.net/plugins/hough-circle-transform
· Kathuria, A. (n.d.). Data Augmentation for Bounding Boxes: Rotation and Shearing. Retrieved 04 05, 2022, from https://blog.paperspace.com/data-augmentation-for-object-detection-rotation-and-shearing/
· Kembhavi, A., Harwood, D., & Davis, L. S. (2010). Vehicle detection using partial least squares. IEEE Transactions on Pattern Analysis and Machine Intelligence, 33(6), 1250-1265.
· Kim, J., Candemir, S., Chew, E. Y., & Thoma, G. R. (2018). Region of Interest Detection in Fundus Images Using Deep Learning and Blood Vessel Information. 2018 IEEE 31st International Symposium on Computer-Based Medical Systems (CBMS), 357-362.
· Kimber, R. M. (1980). LR942 The traffic capacity of roundabouts. Transport and Road Research Laboratory.
· Krajewski, R., Bock, J., Kloeker, L., & Eckstein, L. (2018). The highD Dataset: A Drone Dataset of Naturalistic Vehicle Trajectories on German Highways for Validation of Highly Automated Driving Systems. 2018 21st International Conference on Intelligent Transportation Systems (ITSC), 2118-2125.
· Krajewski, R., Bock, J., Moers, T., & Vater, L. (n.d.). ExiD. The Exits and Entries Drone Dataset. Naturalistic Trajectories of Vehicles Recorded at Exits and Entries of German Highways . Retrieved 03 26, 2022, from https://www.exid-dataset.com/
· Krajewski, R., Moers, T., Bock, J., Vater, L., & Eckstein, L. (2020). The rounD Dataset: A Drone Dataset of Road User Trajectories at Roundabouts in Germany. 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), 1-6, 2020.
· Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2017). ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM, 60(6), 84–90.
· Kukkala, V. K., Tunnell, J., Pasricha, S., & Bradley, T. (2018). Advanced Driver- Assistance Systems: A Path Toward Autonomous Vehicles. IEEE Consumer Electronics Magazine, 18-25.
· Lin, T.-Y., Goyal, P., Girshick, R., He, K., & Dollár, P. (2020). Focal loss for dense object detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(2), 318-327.
· Liu, K., & Mattyus, G. (2015). Fast Multiclass Vehicle Detection on Aerial Images. IEEE Geoscience and Remote Sensing Letters, 12(9), 1938-1942.
· Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.-Y., & Berg, A. (2016). Ssd: Single shot multibox detector. European conference on computer vision.
· Macioszek, E. (2020). Roundabout Entry Capacity Calculation—A Case Study Based on Roundabouts in Tokyo, Japan, and Tokyo Surroundings. Sustainability, 12, 1533.
· Marlow, M., & Maycock, G. (1982). SR724 The effect of Zebra crossings on junction entry capacities. Crowthorne: Transport and Road Research Laboratory.
· Mauro, R., & Guerrieri, M. (2012). Right-turn Bypass Lanes at Roundabouts: Geometric Schemes and Functional Analysis. Modern Applied Science, 7.
· Michon, J. (1993). Generic Intelligent Driver Support: A Comprehensive Report on GIDS.
· Microsimulation, P. (2011). S-Paramics (Parallel Microscopic Traffic Simulator).
· Montgomery, F., Tenekeci, G., & Wainaina, S. (2010). Roundabout capacity in adverse weather and light conditions. Proceedings of The Institution of Civil Engineers-transport - PROC INST CIVIL ENG-TRANSPORT, 163, 29-39.
· Naranjo, J., Sotelo, M.-A., Gonzalez, C., Garcia, R., & Pedro, T. (2007). Using Fuzzy Logic in Automated Vehicle Control. Intelligent Systems, IEEE, 22, 36-45.
· O'Kane, S. (2018, 04 19). How Tesla and Waymo are tackling a major problem for self- driving cars: data. Retrieved 01 01, 2022, from https://www.theverge.com/transportation/2018/4/19/17204044/tesla-waymo- self-driving-car-data-simulation
· OpenCV. (n.d.). Canny Edge Detector . Retrieved 01 16, 2023, from https://docs.opencv.org/4.x/da/d5c/tutorial_canny_detector.html
· OpenCV. (n.d.). Image Thresholding . Retrieved 01 15, 2023, from https://docs.opencv.org/4.x/d7/d4d/tutorial_py_thresholding.html
· OpenCV. (n.d.). Morphological Transformations. Retrieved 01 15, 2023, from https://docs.opencv.org/3.4/d9/d61/tutorial_py_morphological_ops.html
· OpenCV. (n.d.). Operations on arrays. Retrieved 01 15, 2023, from https://docs.opencv.org/3.4/d2/de8/group__core__array.html#ga6fef31bc8c4071cbc114a758a2b79c14
· OpenCV. (n.d.). Smoothing Images. Retrieved 01 15, 2023, from https://docs.opencv.org/4.x/d4/d13/tutorial_py_filtering.html
· OpenCV. Open Source Computer Vision. (n.d.). Hough Circle Transform . Retrieved 01 16, 2023, from https://docs.opencv.org/3.4/d4/d70/tutorial_hough_circle.html
· OpenCV. Open Source Computer Vision. (n.d.). Hough Line Transform . Retrieved 01 16, 2023, from https://docs.opencv.org/4.x/d9/db0/tutorial_hough_lines.html
· Popular Science. (2021, 12 30). Tesla caps off a tumultuous year with a massive recall. Retrieved 12 31, 2022, from https://www.popsci.com/technology/tesla-recalls-vehicles-safety-issues/
· Puertas, E., De-Las-Heras, G., Fernández-Andrés, J., & Sánchez-Soriano, J. (2022). Dataset: Roundabout Aerial Images for Vehicle Detection. Data, 7(4).
· Rebaza, J. (2007). Detección de Bordes Mediante el Algoritmo de Canny. Master’s Thesis. Trujillo, Peru: Universidad Nacional de Trujillo.
· Redmon, J., & Farhadi, A. (2017). YOLO9000: Better, faster, stronger. Proceedings of the IEEE conference on computer vision and pattern recognition.
· Redmon, J., & Farhadi, A. (2018). YOLOv3: An incremental improvement. arXiv preprint arXiv:1804.02767.
· Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You only look once: Unified, real-time object detection. Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, 779–788.
· Ren, S., He, K., Girshick, R., & Sun, J. (2017). Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(6), 1137-1149.
· Robicquet, A., Sadeghian, A., Alahi, A., & Savarese, S. (2016). Learning Social Etiquette: Human Trajectory Prediction In Crowded Scenes. European Conference on Computer Vision (ECCV).
· Rodrigues, M., Gest, G., McGordon, A., & Marco, J. (2017). Adaptive behaviour selection for autonomous vehicle through naturalistic speed planning. 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), 1-7.
· Rodríguez, J. I. (2014). Cómo circular por una glorieta. Tráfico y seguridad Vial, Septiembre-Octubre(228), 28-30.
· Rosebrock, A. (2015). Zero-Parameter, Automatic Canny Edge Detection with Python and OpenCV. Retrieved 01 16, 2022, from https://www.pyimagesearch.com/2015/04/06/zero-parameter-automatic-canny-edge-detection-with-python-and-opencv/
· scikit-image development team. (n.d.). Circular and Elliptical Hough Transforms. Retrieved 01 16, 2022, from https://scikit-image.org/docs/stable/auto_examples/edges/plot_circular_elliptical_hough_transform.html
· Sermanet, P., Eigen, D., Zhang, X., Mathieu, M., Fergus, R., & Lecun, Y. (2013). Over Feat: Integrated Recognition, Localization and Detection using Convolutional Networks. arXiv preprint arXiv:1312.6229.
· Shehata, A., Mohammad, S., Abdallah, M., & Ragab, M. (n.d.). A survey on Hough transform, theory, techniques and applications. arXiv 2015, arXiv:1502.02160.
· Shen, J., Liu, N., & Sun, H. (2021). Vehicle detection in aerial images based on lightweight deep convolutional network. IET Image Processing, 15(2), 479-491.
· Silva, A., Vasconcelos, A., & Santos, S. (2014). Moving from Conventional Roundabouts to Turbo-Roundabouts. Procedia - Social and Behavioral Sciences, 111, 137-146.
· Soleimani, A., & Nasrabadi, N. M. (2018). Convolutional Neural Networks for Aerial Multi-Label Pedestrian Detection. 2018 21st International Conference on Information Fusion (FUSION), 1005-1010.
· Soviany, P., & Ionescu, R. (2018). Optimizing the Trade-off between Single-Stage and Two-Stage Object Detectors using Image Difficulty Prediction. In Proceedings of the 2018 20th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing.
· Sreedhar, K., & Panlal, B. (2012). Enhancement of images using morphological transformations. Int. J. Comput. Sci. Inf. Technol(4), 33–50.
· Stuparu, D.-G., Ciobanu, R.-I., & Dobre, C. (2020). Vehicle Detection in Overhead Satellite Images Using a One-Stage Object Detection Model. Sensors, 20(22).
· Systems, T.-T. S. (2011). Aimsun (Advanced Interactive Microscopic Simulator for Urban and Non-Urban Networks).
· Tan, L., Huangfu, T., & Wu, L. (2021). Comparison of RetinaNet, SSD, and YOLO v3 for real-time pill identification. BMC Medical Informatics and Decision Making, 21.
· Tang, T., Zhou, S., Deng, Z., Zou, H., & Lei, L. (2020). Vehicle detection in aerial images based on region convolutional neural networks and hard negative example mining. Sensors, 20(22).
· The New York Times. (2021, 04 18). 2 Killed in Driverless Tesla Car Crash, Officials Say. Retrieved 12 31, 2022, from https://www.nytimes.com/2021/04/18/business/tesla-fatal-crash-texas.html
· Tollazzi, T., Rencelj, M., & Turnsek, S. (2011). New Type of Roundabout: Roundabout with “Depressed” Lanes for Right Turning – “Flower Roundabout”. PROMET - Traffic&Transportation, 23.
· Troutbeck, R. J. (1989). SR45 evaluating the performance of a roundabout.
· Viola, P., & Jones, M. (2001). Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference, 1.
· Viola, P., & Jones, M. (2004). Robust real-time face detection. Int. J. Comput. Vis., 57, 137–154.
· World Health Organization. (2021, 06 21). Road traffic injuries. Retrieved 12 31, 2022, from https://www.who.int/news-room/fact-sheets/detail/road-traffic-injuries
· World Health Organization. (n.d.). Decade of Action for Road Safety 2011–2020. Retrieved 12 30, 2022, from https://www.who.int/publications/i/item/decade-of-action-for-road-safety-2011- 2020
· Xie, Y., & Ji, Q. (2002). A new efficient ellipse detection method. Pattern Recognition, 2002. Proceedings. 16th International Conference on, 2.
· Yap, Y. H., Gibson, H. M., & Waterson, B. J. (2013). An International Review of Roundabout Capacity Modelling. Transport Reviews, 33(5), 593-616.
· Yap, Y. H., Gibson, H., & Waterson, B. (2015). Models of Roundabout Lane Capacity. Transportation engineering journal of ASCE, 141.
· Yu, Y., Gu, T., Guan, H., Li, D., & Jin, S. (2019). Vehicle detection from high-resolution remote sensing imagery using convolutional capsule networks. IEEE Geoscience and Remote Sensing Letters, 16(12), 1894-1898.
· Zhong, J., Lei, T., & Yao, G. (2017). Robust Vehicle Detection in Aerial Images Based on Cascaded Convolutional Neural Networks. Sensors, 17(12).
· Zoph, B., Cubuk, E., Ghiasi, G., Lin, T.-Y., Shlens, J., & Le, Q. (2020). Learning Data Augmentation Strategies for Object Detection. Computer Vision - ECCV 2020, 566-583.
· Zou, Z., Shi, Z., Guo, Y., & Ye, J. (2019). Object Detection in 20 Years: A Survey. arXiv:1905.05055v2.